
As I’ve worked with clients on performance tuning through index improvements, one of the common areas that I discuss with them are duplicate indexes. The problem with duplicate indexes is that they are pointless and redundant. All they provide is an additional physical copy of the index and all you get is another index for SQL Server update and maintain. Seems like a fairly raw deal.
To help with identifying duplicate indexes, I often leverage the sp_IndexAnalysis stored procedure, as discussed in the companion blog posts, that I put together over the years. This procedure has a duplicate index output mode that has done a decent job of identifying indexes. Unfortunately, after some discussions with some peers and thinking about the internals that I discussed in Expert Performance Indexing for SQL Server 2012, there are some misconceptions that I, and possibly others, have had in regards to what a duplicate indexes are and how to identify them.
What Is A Duplicate Index?
Before looking at how to find duplicate indexes, let’s first look at what constitutes a duplicate index. When looking at an index, there are a number of properties where, if identical to another index, would be considered a duplicate. These properties are:
- Index type
- Key columns
- Sort order of key columns
- Included columns
- Uniqueness
- Filter expression
When considering these properties, there are two generally accepted methods for identifying duplicates. The first is comparing the metadata for the index. In this method, the metadata properties listed above are compared between indexes to find those with exact matches across all of the properties. This is the more popular method for identifying duplicate indexes. The other method is to compare the physical design of the index. While it might seem that comparing the metadata for the index would cover this, depending on the clustered index and the columns that are included in an index, the physical design can sometimes be less intuitive. In this post, we are going to look at a process for identifying physically duplicate indexes.
Now before we look at some duplicate indexes, there are a number of other properties for an index that are not considered when finding duplicates. The primary reason for excluding these properties is that given the properties for determining duplicates, the variations between one value or another for the non-duplicate properties is more correct than the other. For instance, with two duplicate indexes with different fill factor, one of the two values is going to better balance the rate of page splits to size of the index. The same goes for some of the other non-duplicate properties; which include padding, row locks, and page locks. When you do identify a duplicate index, you will need to consider these properties to determine what the “correct” remaining index should have.
METADATA Duplicate Indexes
With the definition of a duplicate index set, the next piece before getting to the script for identifying duplicate indexes is to validate that there is a difference between metadata and physical duplicate index matches. To start, we would easily be able to look at the two indexes at the end of Listing 1 and see that they are duplicate indexes. They are on the same table and have the same key column – the FirstName column.
--Listing 1. Obvious duplicate indexes USE tempdb GO CREATE TABLE dbo.Person ( PersonID INT IDENTITY(1,1) ,FirstName VARCHAR(50) ,LastName VARCHAR(50) ,CONSTRAINT PK_Person PRIMARY KEY CLUSTERED (PersonID) ) INSERT INTO dbo.Person SELECT FirstName, LastName FROM AdventureWorks2012.Person.Person CREATE INDEX IX_Person_FirstName ON dbo.Person(FirstName) CREATE INDEX IX_Person_FName ON dbo.Person(FirstName)
In the typical metadata script for finding duplicate indexes, such as the one provided in Listing 2, this is exactly the type of duplicate indexing you would be uncovering. It’s fairly straightforward, and easy to validate that it is indeed a duplicate index, as shown in Figure 1. The indexes have the same key columns, uniqueness, filter definition, included columns, and sort order.
--Listing 2. Metadata Duplicate Index Script
WITH IndexSchema AS (
SELECT i.object_id
,i.index_id
,i.name
,ISNULL(i.filter_definition,'') AS filter_definition
,i.is_unique
,(SELECT CASE key_ordinal WHEN 0 THEN NULL ELSE QUOTENAME(CAST(column_id AS VARCHAR)
+ CASE WHEN ic.is_descending_key = 1 THEN '-' ELSE '+' END,'(') END
FROM sys.index_columns ic
WHERE ic.object_id = i.object_id
AND ic.index_id = i.index_id
ORDER BY key_ordinal, column_id
FOR XML PATH('')) AS index_columns_keys_ids
,(SELECT CASE key_ordinal WHEN 0 THEN QUOTENAME(column_id,'(') ELSE NULL END
FROM sys.index_columns ic
WHERE ic.object_id = i.object_id
AND ic.index_id = i.index_id
ORDER BY column_id
FOR XML PATH('')) AS included_columns_ids
FROM sys.tables t
INNER JOIN sys.indexes i ON t.object_id = i.object_id
WHERE i.type_desc IN ('NONCLUSTERED'))
SELECT QUOTENAME(DB_NAME()) AS database_name
,QUOTENAME(OBJECT_SCHEMA_NAME(is1.object_id)) + '.'
+ QUOTENAME(OBJECT_NAME(is1.object_id)) AS object_name
,is1.name as index_name
,is2.name as duplicate_index_name
FROM IndexSchema is1
INNER JOIN IndexSchema is2 ON is1.object_id = is2.object_id
AND is1.index_id is2.index_id
AND is1.index_columns_keys_ids = is2.index_columns_keys_ids
AND is1.included_columns_ids = is2.included_columns_ids
AND is1.filter_definition = is2.filter_definition
AND is1.is_unique = is2.is_unique

Figure 1. Results for Metadata Duplicate Index
Physical Index Structure
While matching metadata is a useful method for identifying duplicate indexes, it doesn’t take into account how the index is being physically implemented by SQL Server. This difference can, and does, make a huge difference when you want to remove duplicate indexes from your databases. The aspect that makes reviewing the physical implementation of the indexes important when looking for duplicates is that the clustered index keys are included in all non-clustered indexes.
To demonstrate, let’s first look at the physical structure of the two indexes created in Listing 1. We can do this by running DBCC IND against the two indexes by providing the index id and using the T-SQL statement in Listing 3. The output from this command is provided in Figure 2, which shows that pages 536 and 648 are the first index pages for these two indexes, these page numbers may differ on your server.
--Listing 3. DBCC IND for First Two Indexes USE tempdb GO DBCC IND (0,'dbo.Person',2) DBCC IND (0,'dbo.Person',3)
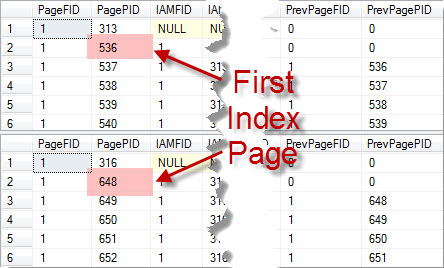
Figure 2. Results for DBCC IND on First Two Indexes
Taking the page numbers from the first two pages, we next want to use DBCC PAGE to return back all of the entries from the index pages. The script in Listing 4 provides the commands using the pages already identified and returns the results in Figure 3. The results contain one item of interest, the PersonID column is part of the index as a key column. It’s interesting because PersonID was not a key column in the non-clustered indexes. This is the intended behavior with SQL Server, clustering key values are included in non-clustered keys and they comprise a portion of the key for the non-clustered index. Reviewing these results, we also see that the initial information in both indexes is identical and this continues to the end of the index (trust me, I’m a consultant).
--Listing 4. DBCC PAGE for First Two Indexes USE tempdb GO DBCC TRACEON(3604) DBCC PAGE(0,1,536,3) -- Index page for first index DBCC PAGE(0,1,648,3) -- Index page for second index
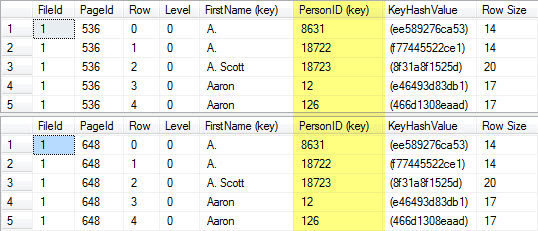
Figure 3. Results for DBCC PAGE on First Two Indexes
At this point, we’ve validated what we already know. Indexes with identical metadata have the same physical structures. We also saw a validation that the clustering key is included in non-clustered indexes. The next step is to look at indexes that are not metadata duplicates and see if there is something missing in the duplicate index script that might provide better results when it comes to uncovering index duplication.
For the next set of indexes, we’re going to look at the impact of included columns and the clustering key on non-clustered indexes. Two additional indexes will be created, provided in Listing 5. The first index includes PersonID in the index as data. The second index contains PersonID as one of the key columns. Neither of these indexes are duplicates of any of the other indexes, when you consider duplication from a metadata perspective. Running the code in Listing 2 will still return the results in Figure 1.
--Listing 5. Create Script for Second Set of Indexes USE tempdb GO CREATE INDEX IX_Person_FirstNameINC ON dbo.Person(FirstName) INCLUDE (PersonID) CREATE INDEX IX_Person_FirstNamePersonID ON dbo.Person(FirstName, PersonID)
As already discussed, the clustering index key is included in the keys for non-clustered indexes. This was proven in the previous indexing example, when we reviewed the page entries. What happens then, when the PersonID column is part of a non-clustered index as either an included column or key column, as was done with the two indexes that were just added?
We’ll investigate by again using DBCC IND to find the first index pages of the index, using the code in Listing 6. In this case, the first pages are page 744 and 848 for the third and fourth index created, respectively, shown in Figure 5.
--Listing 6. DBCC PAGE for First Two Indexes USE tempdb GO DBCC IND (0,'dbo.Person',4) DBCC IND (0,'dbo.Person',5)

Figure 5. Results for DBCC IND on Second Two Indexes
Using those page numbers, we can then use DBCC PAGE, provided in Listing 7, to look at the structure of the index. The interesting part here is the inclusion of the PersonID as a key column in the index. As the definition of the index indicates, in the first of the indexes, the PersonID column is in included column in the index but it is still is listing PersonID as a key column. This is due to the PersonID column being the clustering key for the table. Digging deeper into the DBCC IND results for all of the indexes would show that there are no data pages and the same number of pages allocated between all four indexes. With the second of indexes in this set, the PersonID is a key column already, thus it doesn’t need to be added to the index.
--Listing 7. DBCC PAGE for First Two Indexes USE tempdb GO DBCC TRACEON(3604) DBCC PAGE(0,1,744,3) -- Index page for third index DBCC PAGE(0,1,848,3) -- Index page for four index

Figure 6. Results for DBCC PAGE on Second Two Indexes
In the end, all four of the indexes are the same. Or at least the same from a physical standpoint. The options used to create the four indexes vary between them, but when SQL Server builds all of these indexes the same data and structure will be built. The ability to identify duplicates at the physical level is important because these are just more and more indexes that you are maintaining and expending resources on – without any gain.
Physically Duplicate Index Script
Fortunately, uncovering physically duplicates isn’t that difficult to accomplish. Starting with the duplicate index script from earlier in this post, a couple JOINS and a UNION ALL with the metadata of the clustered index provides all of the information needed to get the complete picture. The code provided in Listing 8 accomplishes this task and provides a list of all of the physically duplicate indexes in the database, as shown in Figure 7.
--Listing 8. Physically Duplicate Index Script
WITH IndexSchema AS (
SELECT i.object_id
,i.index_id
,i.name
,ISNULL(i.filter_definition,'') AS filter_definition
,i.is_unique
,(SELECT QUOTENAME(CAST(ic.column_id AS VARCHAR(10))
+ CASE WHEN ic.is_descending_key = 1 THEN '-' ELSE '+' END, '(')
FROM sys.index_columns ic
INNER JOIN sys.columns c ON ic.object_id = c.object_id AND ic.column_id = c.column_id
WHERE i.object_id = ic.object_id
AND i.index_id = ic.index_id
AND is_included_column = 0
ORDER BY key_ordinal ASC
FOR XML PATH(''))
+ COALESCE((SELECT QUOTENAME(CAST(ic.column_id AS VARCHAR(10))
+ CASE WHEN ic.is_descending_key = 1 THEN '-' ELSE '+' END, '(')
FROM sys.index_columns ic
INNER JOIN sys.columns c ON ic.object_id = c.object_id AND ic.column_id = c.column_id
LEFT OUTER JOIN sys.index_columns ic_key ON c.object_id = ic_key.object_id
AND c.column_id = ic_key.column_id
AND i.index_id = ic_key.index_id
AND ic_key.is_included_column = 0
WHERE i.object_id = ic.object_id
AND ic.index_id = 1
AND ic.is_included_column = 0
AND ic_key.index_id IS NULL
ORDER BY ic.key_ordinal ASC
FOR XML PATH('')),'')
+ CASE WHEN i.is_unique = 1 THEN 'U' ELSE '' END AS index_columns_keys_ids
,CASE WHEN i.index_id IN (0,1) THEN 'ALL-COLUMNS' ELSE
COALESCE((SELECT QUOTENAME(ic.column_id,'(')
FROM sys.index_columns ic
INNER JOIN sys.columns c ON ic.object_id = c.object_id AND ic.column_id = c.column_id
LEFT OUTER JOIN sys.index_columns ic_key ON c.object_id = ic_key.object_id AND c.column_id = ic_key.column_id AND ic_key.index_id = 1
WHERE i.object_id = ic.object_id
AND i.index_id = ic.index_id
AND ic.is_included_column = 1
AND ic_key.index_id IS NULL
ORDER BY ic.key_ordinal ASC
FOR XML PATH('')), SPACE(0)) END AS included_columns_ids
FROM sys.tables t
INNER JOIN sys.indexes i ON t.object_id = i.object_id
INNER JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id
INNER JOIN sys.dm_db_partition_stats ps ON i.object_id = ps.object_id AND i.index_id = ps.index_id)
SELECT QUOTENAME(DB_NAME()) AS database_name
,QUOTENAME(OBJECT_SCHEMA_NAME(is1.object_id)) + '.'
+ QUOTENAME(OBJECT_NAME(is1.object_id)) AS object_name
,is1.name as index_name
,is2.name as duplicate_index_name
FROM IndexSchema is1
INNER JOIN IndexSchema is2 ON is1.object_id = is2.object_id
AND is1.index_id is2.index_id
AND is1.index_columns_keys_ids = is2.index_columns_keys_ids
AND is1.included_columns_ids = is2.included_columns_ids
AND is1.filter_definition = is2.filter_definition
AND is1.is_unique = is2.is_unique

Figure 7. Results for Physically Duplicate Index
Summary
In this post, we explored the differences between metadata and physically duplicate indexes. While metadata indexes do give good insight into duplicate indexes, you really need to look further than that to get the complete story. As you review the indexes in your environment, you may find some that do have physical layouts or statistics that are different – even though they are pegged as being physical duplicates. There are a few things that can contribute to this – namely when the index was created, when the last defragmentation occurred, when the statistics were last updated. If you’re looking for a better formatted output for the physical duplicate indexes, check out the March update for the sp_IndexAnalysis stored procedure which is due out on March 7.
What are your thoughts? Did I miss anything? Please comment below.
UPDATE
As mentioned in the comments, these duplicates are purely focused on non-clustered indexes. For other index types, XML, ColumnStore, and spatial, I haven’t looked at this topic in that regard.

Great article and food for thought. I spend a lot of time clearing up indexes so we created a tool called Aireforge Studio that will check for duplicate, overlapping, missing, redundant and possibly unique indexes from a GUI. You can download the free trial from http://www.aireforge.com.
LikeLike
Light grey over white. OW.
LikeLike
Very well written easily understandable. Thank you.
LikeLike
Jason – I saw an extended events presentation you gave at a SQL Saturday in San Diego years ago, and I really enjoyed it!
I think it would be good to be clear about where/when the cluster key gets added to a non-clustered index. The statement “…clustering key values are included in non-clustered keys and they comprise a portion of the key for the non-clustered index” is incomplete. While they always exist at the leaf level of a non-clustered index of a table with a clustered index on it, they exist in the key of the non-clustered index only when the clustering key is not unique.
This aids in the traversal of the index by making the key unique, since the cluster key is forced to be unique.
LikeLike
It would be nice if you could elaborate on overlapping indexes as well in another blog post. With overlapping indexes I mean for example one index on LastName only and another index on LastName and FirstName (in that order). Could the engine also use the second index in a query on LastName only or does the first index really improves query performance in that case?
LikeLike
Thanks for the comment. I’m actually planning on this. I’m retying to figure out how I want to define overlapping indexes still. By bringing in the clustering key columns to the equate, the key columns for the index are changed. So, do we remove the clustering keys and consider just the core indexing keys? Or consider it all? I’m planning to run some tests to figure out what makes the most sense.
LikeLike
In Listing 4, the first first dbcc page command is:
DBCC PAGE(0,1,648,3) — Index page for first index
Shouldn’t it be:
DBCC PAGE(0,1,536,3) — Index page for first index
LikeLike
Good catch on the typo. Fixed the script and the image – bad job on my part copying the scripts over to the blog post. Fortunately, it doesn’t change anything as far as the content goes.
LikeLike
No problem! Truly excellent post.
LikeLike
Nice post. Also worth noting that it doesn’t apply to all index types. For example I could imagine two spatial indexes that are identical apart from tesselation levels.
LikeLike
Thanks, Greg. Very true. At this point, it really only applies to non-clustered indexes. I’ll get a note on that in here.
LikeLike
This is a really detailed, well written post nice job 🙂
LikeLike
Thanks. I drilled a few people at MVP Summit to check sure I was right on this before putting it together.
LikeLike