
The last post discussed the Pivot transformation – that leads us to this post which will be on the Unpivot Transformation. Part of the reason I had been trying to fit the the Pivot transformation into the issue I was having was also because I knew how to use the Unpivot transformation and thought I had better know how to use the Pivot transformation.
Let’s reverse that psychology and for this 31 Days of SSIS post we’ll look at this transformation and what it can do. In the end, we’ll wrap up with why I began using this transformation in the first place. And provide some ideas on how you can use it in the future.
As the name suggests, the Unpivot transformation will unpivot data in a result set. Unfortunately, definitions should use their own self to define themselves. A better way to state this is that values in multiple columns can be transformed into a single column. The end result is to take normalized result set and return name-value pairs instead.
Consider a result set where sales information for each year is stored in a year column. Unpivoting the data would result in a row for every year instead of a column for each year. The data would transform similar to the image below:
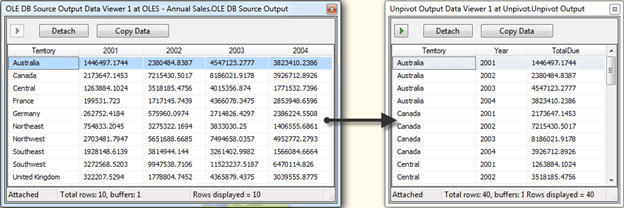
To demonstrate the use of the Unpivot transformation, we’ll go through building a package with the transformation.
 Package Control Flow
Package Control Flow
Another fairly simple SSIS package. To start add a Data Flow task to the Control Flow. No variables or special configurations will be needed for this package. Go next to the Data Flow task.
Package Data Flows
Simple package. Simple data flow. Since there is only this one we’ll just right into that data flow and it’s transformations.
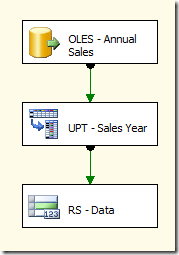
DFT – Unpivot Transformation
The transformations in the data flow are the following:
- OLES – Annual Sales: OLE DB Source to the AdventureWorks database. The data source retrieves sales data with columns for each year.
- UPT – Sales Year: Unpivot transformation that will unpivot the sales data by year. For each column, there will be one row returned. configuration of this transformation will be described in detail below.
- RS – Data: Row Sampling transformation that is included just to demonstrate the data movement.
Unpivot Transformation Configuration
To start configuring the Unpivot transformation, double-click on it. When this is done, the Unpivot Transformation Editor will open. Fortunately, the Unpivot transformation has an editor that doesn’t require the use of the Advanced Editor for Unpivot Transformation. In fact, there isn’t much of use in trying to use the Advance Editor over the regular editor.
Let’s take a look at how to configure the Unpivot transformation. Initially, you’ll see that the columns from the input are listed in a selection area at the top of the window. Initially all of the columns will be configured for Pass Through.

The intention is to return all of the data in the year columns (2001, 2002, 2003, and 2004) in a single column. The values in the rows for these columns are the Total Due dollars. To start this, select the year columns on the left-side checkboxes. Doing this will add these columns as Input Columns.

After each column is selected, change the value of the Destination Column to Total Due. This setting will create the column where the value of each row in the column will be placed.
Optionally, the Pivot Key Value can be modified to change the value that each row will have in the name-value pair. For instance, if the data in the 2001 column should be on a row with a value of “Year-2001” instead of “2001” then this is where that configuration will be made.
The last step is to name the column that the Pivot Key Values will be populated into. That is done with the last setting available in the window. The Pivot key value column name: text box. Type Year in that box and click OK.

At this point, the configuration of the Pivot transformation is complete. First off the package and the output will be identical to what was in the introduction.
Unpivot Transformation Wrap-Up
Now you know how to use the Unpivot transformation. It’s simple and not too confusing. The next question is what solutions would require the use of this transformation.
It’s true, you could use it to unpivot data as it comes out of your SQL Server and prepare it to be delivered to end users for reporting. But in many of those cases, the data would be probably better unpivoted at the source. Or most likely isn’t being stored in a manner that requires and unpivot operation.
The case where I get the most use of the Unpivot transformation is when loading data into client databases. Many of the clients I work with have a need to import data from their customers to their database. Each of data sets from their customer’s data has their own nuances. This variation leads to the need for a set of tables that are designed to store name-value pairs.
Sometimes, I load up the client data to staging tables and then do the transfer of each of the columns from the source file to the destination column. The problem here is that it can be tedious to setup. With many different files to configure and load there is an appeal to using the unpivot to prepare the data in the name-value pair while importing it. As opposed to creating custom structures for each column in each file.
In this use case, the unpivot operation has been extremely helpful. Previously, I would previously designed tables and write stored procedures. Now, I click, click, click. Write a couple column names. Then the work is done. It’s like magic.
That should cover the Unpivot transformation. If there are any questions feel free to leave a comment.

Hi, We had a requirement to unpivot data from an excel file where data was in Pivot form. However, using Excel as data source under data flow task was failing to read the data in pivoted form. Seems it only accepts data in tabular form. Is there a known workaround this? Please suggest.
LikeLike