
A few months back, well before the 31 Days of SSIS started, I had been playing with the Pivot Transformation. The transformation seemed to fit an issue that I was working through. After getting to a point where I wanted to smash my computer I finally figured out how to use it and thought this would be great to share.
The Pivot transformation does pretty much exactly what that name implies. It pivots data along an x-axis which is determined by values in a column. Another column of value are used along the y-axis to determine the columns to include. Since this columns on the y-axis are determined by the data in the source there is some configuring in the Pivot transformation that needs to occur to properly pivot data.
On a general sense, with the Pivot transformation you are taking data similar to that on the left in the image below. Then transforming it into a data set similar to the data on the right.
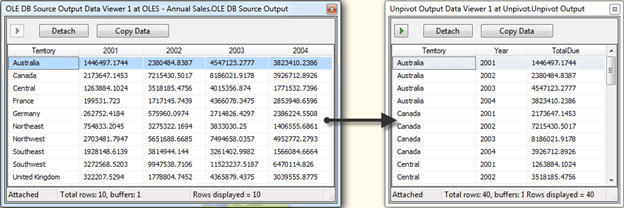
To demonstrate the use of the Pivot transformation, we’ll go through building a package with the transformation.
 Package Control Flow
Package Control Flow
This package will be fairly simple. Start by adding a Data Flow take to the Control Flow. After that’s done, we’re done with the Control Flow. No variable or special configuration for this package.
Package Data Flows
Similar to the control flow, the data flow is going to be very simple. Only one of the transformations in the data flow will be of interest in this case but we’ll go through all of it just the same.
 DFT – Pivot Transformation
DFT – Pivot Transformation
The transformations in the in data flow are the following:
- OLES – Annual Sales: OLE DB Source to the AdventureWorks database. The data source retrieves sales data.
- PVT – Sales Year: Pivot transformation that will pivot sales data from one record per territory per year to one record per territory with years as columns. The configuration of this transformation will be described in detail below.
- RS – Data: Row Sampling transformation that is included just to demonstrate the data movement.
Pivot Transformation Configuration
To start configuring the Pivot transformation, double-click on it. By doing this the Advanced Editor for the transformation will open. Unlike most other transformations, the Pivot transformation is always configured from the Advanced Editor.
Component Properties
The first tab to configure is the Component Properties. For the most part you won’t change anything on this tab. I mention the tab just for completeness in describing the configuration.
 Input Columns
Input Columns
The first place to make configuration changes will be on the Input Columns tab. This tab lists all of the columns available from the input to the transformation. For this example, select all of the columns. For your data, pass through the columns that you will need.
Input and Output Properties
This is the part takes nearly all of the configuration. I recommend grabbing a pen and paper to take notes as you set this up. Getting the configuration values correct will be critical.
To start with expand the Pivot Default Input folder in the tree view. This will show the three columns that were selected in the previous tab.
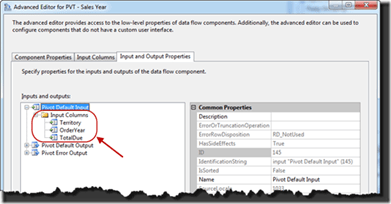
From here highlight the Territory column. In the properties window take note of two of the properties; LineageID and PivotUsage. LineageID will be used in configuring future properties of the transformation. The PivotUsage should be set to 1. This value configures this column to be part of the x-axis of the pivot. Rows will be grouped across this column.
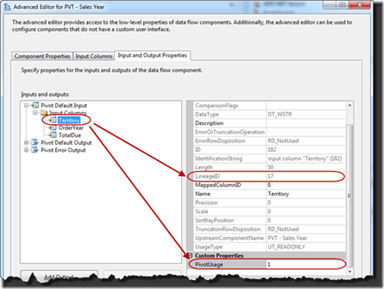
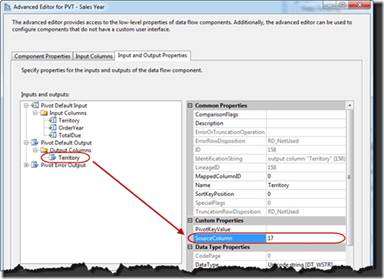
Now expand the Pivot Default Output. There will be no output columns in the output. Start by selecting the button Add Column. Name the new column Territory.
In the properties for the new column change the value for the SourceColumn property to 17. This is the value that was just noted above.
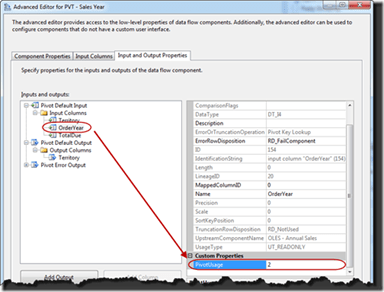
Back in the Pivot Default Input select the OrderYear column. Change the value for the PivotUsage on this column from 0 to 2. The value of 2 configures the column to be the y-axis of the pivot. The values in this column will be used to create new columns in the pivot operation.
Going back up to the Pivot Default Input. Select the TotalDue column. Change the PivotUsage for this column to 3. The value of 3 configures the values in the columns to be placed in the new columns create by pivoting the data. Take note of the LineageID as this will be used for configuring in the next step.
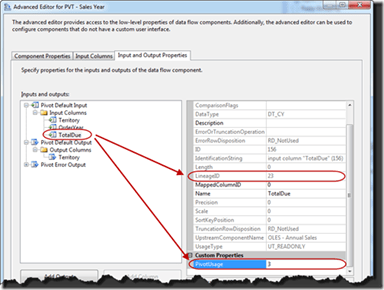
The final step will be to add four new columns to the Pivot Default Output folder. These columns should be named 2001, 2002, 2003, and 2004. The name of the columns doesn’t necessarily matter.
For each of the columns, configure the PivotKeyValue and SourceColumn properties. The value for the PivotKeyValue property will be the value in the OrderYear column for that column. For the 2001 column the value of the property will be 2001. For the SourceColumn property use the LineageID from above.
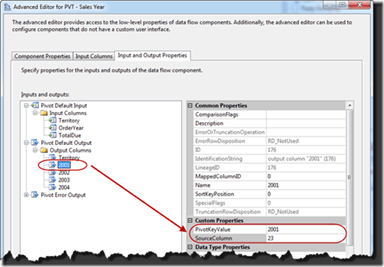
At this point, the Pivot transformation is configured. Select the OK button to close out the window. Then run the the SSIS package.
Pivot Transformation Wrap-Up
Once you’ve setup your first Pivot transformation, you’ll see that it isn’t that difficult to use. It’s a bit tricky the first few times since it doesn’t have an easy interface like many of the other transformations.
There are a few considerations that you need to take into account when using a Pivot transformation. These are important and your mileage will suck if you forget these:
- The Pivot transformation expects, but not check for, sorted inputs. The x-axis values need to be grouped together to get the correct output. SSIS will not error if you forget to do this.
- The Pivot transformation will error if it encounters a value that has not been handled by the output columns. This is good because you won’t accidentally miss something in the source data. This can be bad if you only want to pivot a subset of the columns to the y-axis.
- Columns that are not part of the pivot operation can be included in the output by setting their PivotUsage value to 0.
That about covers the Pivot transformation. Hopefully this helps if you’ve tried to use this transformation in the past. I know the frustration that setting this transformation up can bring.

very good practical example . it was very easy to understand and implement it ..
LikeLike
Your welcome – it's a useful transformation but a definite pain to implement.
LikeLike
Great series. Good practical examples.
LikeLike
Thank you. I've been glad that these have helped people out. Wasn't sure people would find much use in all of these.
LikeLike
Nice that you are keeping the package of each day blog post.
Want to learn from your post.
Thanks,
Anil Maharjan
LikeLike
Your welcome. Glad these have been helpful.
LikeLike