
One day at a time and we have reached the twenty-fifth post in the 31 Days of SSIS. If you enjoy this post, take a look at other posts in this series. They can be found through the introductory post.
Yesterday’s post demonstrated an SSIS package that connected one package to unlimited databases. For today, I thought I would take it down one more notch and connect one package to unlimited tables.
A while back, I was presented with an interesting situation. There was an archival process that was controlled by a SQL script with hundreds of lines of code. This script would dynamically generate a execution script for the archival process that had tens of thousands of lines of code.
Unfortunately, there were two big problems with this solution. First, maintaining the archival process was a bear. It contained a combination of data in tables, hard-coded configurations in scripts, and extended properties that were required and undocumented. Second, troubleshooting issues was near impossible. Since it was difficult to maintain it was easy for things to get missed. There were also many situations where transactions were started and not committed. Error handling was sporadically implemented and messages that described any issues were lacking.
Package Requirements
Shortly after becoming aware of this situation, I proposed a change in direction from the existing solution to a solution centered on SSIS. The idea was that instead of scripts with thousands of lines of T-SQL, an SSIS package or two could move the data from the production to the archive server. On this server, a generic merge statement could be used to import the new and updated records. The idea was to have some common components that would generically load everything.
One of the major requirements for this was the need to be able to archive data from any number of tables. Initially, the process would cover a couple hundred tables. Over time, though, it might need to archive those plus a few hundred more tables. The solution had to be robust enough that it could expand at any time with minimal configuration.
Unlimited Table Solution
An immediate issue that came up with architecting this solution was that Data Flows in SSIS are strongly typed. If they are configured for there to be 10 columns that are all integer data-types; then that is what they are. There is not capacity to change them at run-time. For this reason, consideration of the use of Data Flow tasks was removed as a part of the solution.
Instead, I opted to turn to a couple technologies that have been around SQL Server for quite some time. These are BCP and BULK INSERT. While SSIS is relatively new, BCP and BULK INSERT have been around for a while. Their age, though, should not be held against them when designing solutions. In the end, we need a solution. Not something built on the latest and greatest. With these two technologies in hand, the SSIS package can be built.
The overall idea will be to take a list of tables that need archived. This can be stored in a table, based on extended properties, or tied into the implementation of other features (such as CHANGETRACKING or Change Data Capture). However you obtain the list of tables, the point is the need for a list that can be placed into a record set.
After that, the list of tables will be used to iterated through with a ForEach Loop. With each table in the loop, the SSIS package will BCP out the data from the table in one database to a file. The file will then imported into the archive database using BULK INSERT.
The last step will be to merge the data imported into the existing tables in the archive database. For the purposes of this demonstration we’ll have a place holder for this but no logic to manage it.
Package Control Flow
 Differing from most other SSIS packages, all of the work in this package will occur in the Control Flow. As discussed above, the control flow will obtain a list of tables. It will then iterate through each of the tables. In each iteration, the package will BCP out the data needed. After which the package will import the data into archive tables.
Differing from most other SSIS packages, all of the work in this package will occur in the Control Flow. As discussed above, the control flow will obtain a list of tables. It will then iterate through each of the tables. In each iteration, the package will BCP out the data needed. After which the package will import the data into archive tables.
There are a number of tasks in the control flow that are needed to implement this solution. Those tasks are:
- SQL_Truncate: Execute SQL task that truncate the data in the archive tables. This is just to help show that the process is functioning. Demo purposes only for this task.
- SQL_ArchiveTableList: Execute SQL task that retrieves a list of tables that need to be archived. In a full implementation this would query the stored list of tables that need to be archived.
- FELC_ArchiveTables: ForEach Loop container that cycles through each of the tables retirenved from the SQL_ArchiveTableList task.
- EPT_BCPData: Execute Process task that runs a BCP.exe command. This task retrieves all of the data for the table and populates it to an output file.
- EPT_BCPFormat: Execute Process task that runs a BCP.exe command. This task retrieves the format for the table. The format will be required to import the data in the next step.
- BLK_ArchiveData: BULK INSERT task that consumes the BCP data and format files. The data is inserted from those files into the archive table.
- SQL_MergeLogic: Execute SQL task that is a placeholder for INSERT, UPDATE, and DELETE logic. This is included for demo purposes to show where this would be located in a larger package.
Package Variables
There are a number of variables in the package to help control how everything is processed.
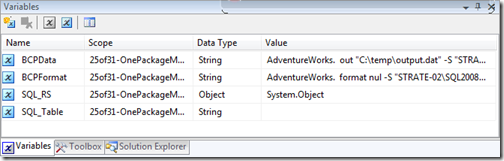
The variables from above were added for the following purposes:
- BCPData: Expression containing the arguments for the BCP utility called in the EPT_BCPData task
- BCPFormat: Expression containing the arguments for the BCP utility called in the EPT_BCPFormat task
- SQL_RS: Record set that contains the list of tables that need to be archived.
- SQL_Table: String variable that contains the name of the current table being archived
Variable Expressions
Part of what makes this package work is the use of the BCP utility. In order for the BCP utility to operate, the arguments for BCP.exe need to change per iteration. The expressions below control this behavior.
- BCPData: “AdventureWorks.” + @[User::SQL_Table] + ” out “C:\temp\output.dat” -S “STRATE-02\SQL2008R2″ -T -c”
- BCPFormat: “AdventureWorks.” + @[User::SQL_Table] + ” format nul -S “STRATE-02\SQL2008R2” -T -c -f “C:\temp\output.fmt””
Package Data Flows
This should have been expected. There are no data flows in this SSIS package.
Unlimited Tables Wrap-Up
There are a number of items that would be included in this solution to flush it out completely. For brevity, I’ve focused this post on the use of BCP and BULK INSERT. Some of the things that were either glanced over or not mentioned are:
- Incremental updates: For most implementations, you will want to only ship a few columns over to the archive server for each execution. Ideally these would be the records that have changed. There are various ways to do this; such as triggers, change date columns, CHANGETRACKING, or Change Data Capture to name a few.
- Foreign key ordering: If the tables in the archive server have foreign key relationships similar to those of the production database, then the tables will need to be processed in the order that doesn’t violate the foreign keys.
- BULK INSERT locality: Not mentioned but a good point to remember, BULK INSERTS need to use files that are local to the SQL Server instance. This means the package will need to be run on the archive server.
- BULK INSERT task: There have been SQL Server 2008 CUs that break the functionality of the BULK INSERT task. In these cases, I’ve recommended switching over from a BULK INSERT task to an Execute SQL task that uses a BULK INSERT statement.
- Staging database: When I’ve used this solution with clients, the data is usually landed to a staging database. This provided a layer of disconnect where the SSIS package could drop and create whatever it needed during processing.
- Staging table schema: One assumption that is being made with the BCP and BULK INSERT process is that the schema and layout of the tables between the two environments are identical. For this reason, I will often re-create the destination tables when the package runs to guarantee the schema.
- Merge piece: The T-SQL to INSERT, UPDATE, and DELETE data that has been imported to the archive database with data was not included. This is primarily because of the limited scope of this post. If you want to guess… it uses dynamic SQL.
What do you think of this solution? It’s honestly one of my favorite designs since I was able to accomplish something I initially thought might not be possible.

How do you accomplish things like auditing the data moving from the source database to the archive db? Surely you must ensure that all rows to be deleted from the source actually made it to the archive first.
LikeLike
Here in the article you indicate that in eacj iteration the argument should be as follows
BCPData: “AdventureWorks.” + @[User::SQL_Table] + “ out ”C:tempoutput.dat” -S ”STRATE-02SQL2008R2” -T -c”
I copyied/pasted this in the variable value but it didnt work neither.
LikeLike
you should set it in expression of variable property window, not in the value field.
LikeLike
Jason, again I would like thank you for your great articles. However, Package is not executing because of BCP.
Can you please let me know where or how the magic happens for concatinating the table name inside the variable BCPData which is
AdventureWorks. out "C: empoutput.dat" -S "SQL2k8" -T -c
in the package.
when running the package I notice in execution result window :
Error: In Executing "C:Program FilesMicrosoft SQL Server100ToolsBinncp.exe" "AdventureWorks. out "C: empoutput.dat" -S "SQL2k8" -T -c" at "", The process exit code was "1" while the expected was "0".
Thanks for your help
LikeLike
These values are applied to the properties through the expressions collections on the data flow and transformations. Check those to see how I have them configured and it should get you to the issue you are encountering. The lack of the table name in the value above will be related to the table name populated by default in the variables.
LikeLike